
L’apprentissage non supervisé : révéler l’invisible à l’ère de l’intelligence artificielle
Introduction
À l’ère des big data et de l’intelligence artificielle, nous produisons chaque jour des masses phénoménales de données : textes, images, vidéos, transactions, signaux numériques. Pourtant, la majorité de ces données est dépourvue d’étiquettes expliquant leur contenu.
Comment extraire de la valeur sans intervention humaine intensive ?
L’apprentissage non supervisé répond à ce défi : en repérant automatiquement structures et modèles cachés, il révolutionne l’analyse de données dans des secteurs aussi variés que la santé, la finance ou le marketing.
Découvrons ensemble pourquoi ce pilier du machine learning est devenu indispensable.
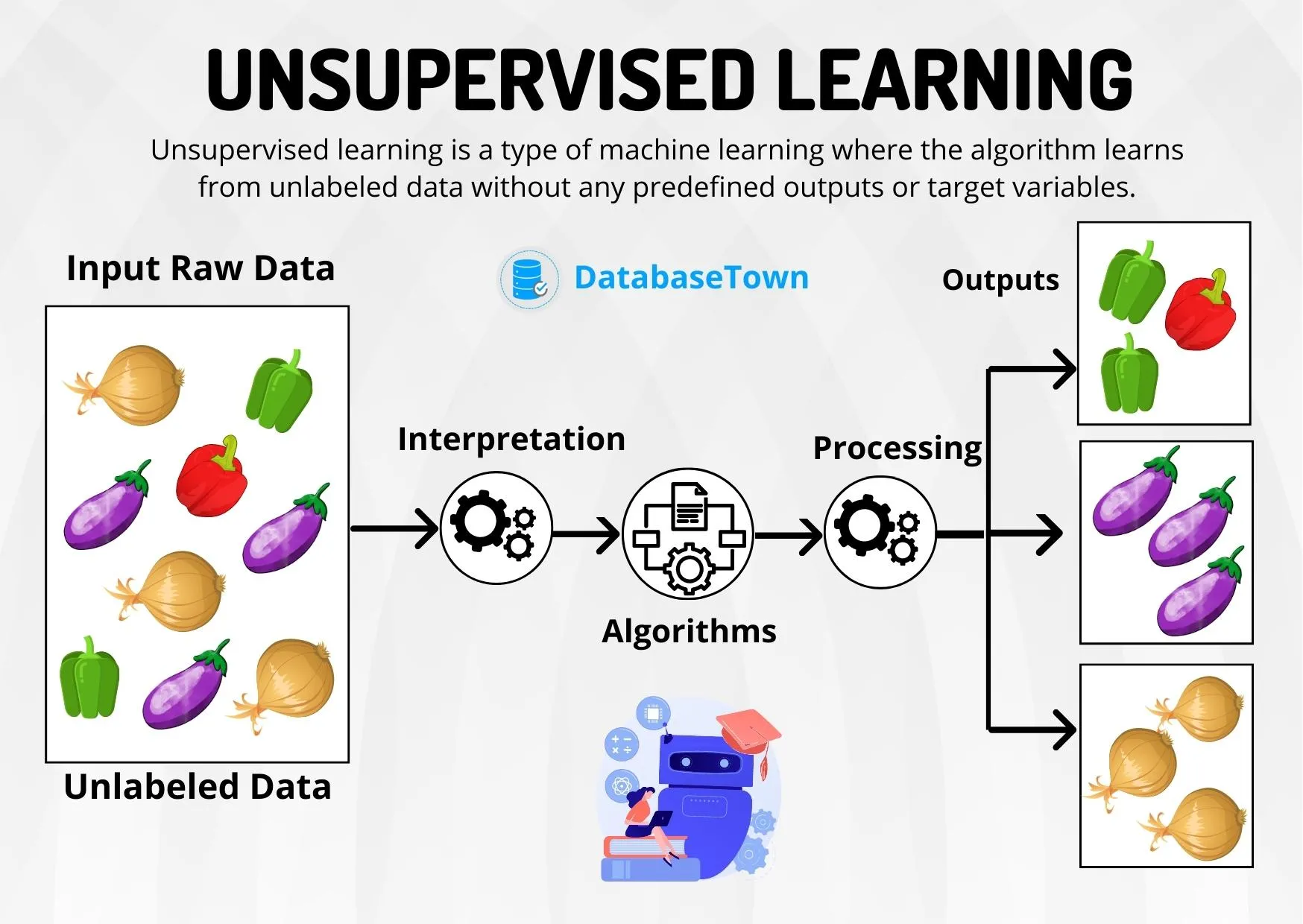
Qu’est-ce que l’apprentissage non supervisé ?
L’apprentissage non supervisé désigne une catégorie d’apprentissage automatique où les algorithmes doivent détecter des patterns dans des données non étiquetées, c’est-à-dire sans indication préalable de leur signification.
Contrairement à l’apprentissage supervisé, qui associe chaque entrée à une sortie spécifique, l’apprentissage non supervisé vise à découvrir des structures intrinsèques aux données.
Objectif : organiser, segmenter ou simplifier les données, sans connaissance a priori.
Comment fonctionne l’apprentissage non supervisé ?
L’apprentissage non supervisé repose principalement sur trois techniques majeures :
Clustering : regrouper des données similaires
Le clustering (ou regroupement) est une technique centrale en apprentissage non supervisé qui consiste à regrouper automatiquement des données similaires entre elles, sans étiquettes préalables. L’objectif est de découvrir une structure ou des motifs cachés dans les données.
🔍 Principe de base
L’algorithme de clustering attribue à chaque donnée un groupe (ou cluster) selon sa ressemblance avec les autres. Ce critère de ressemblance dépend souvent d’une mesure de distance (comme la distance euclidienne).
Par exemple, si tu donnes à un algorithme des points représentant des clients (avec des caractéristiques comme l’âge et les dépenses), il pourra les regrouper en profils types (jeunes dépensiers, retraités économes, etc.) sans savoir à l’avance combien de types existent ni leurs caractéristiques.
⚙️ Algorithmes de clustering populaires
- K-Means
- Divise les données en k groupes en minimisant la distance entre les points et le centre du cluster.
- Nécessite de définir k à l’avance.
- Simple, rapide, mais sensible aux points aberrants.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Regroupe les points denses ensemble.
- Identifie les outliers (bruit) naturellement.
- Ne nécessite pas de définir k, mais des paramètres comme la distance epsilon.
- Efficace pour les formes complexes.
- Hierarchical Clustering
- Crée une hiérarchie de clusters (sorte d’arbre ou dendrogramme).
- Ne nécessite pas toujours de fixer k.
- Peut être agglomératif (du bas vers le haut) ou divisif (du haut vers le bas).
🧠 Applications
- Segmentation de clients en marketing.
- Détection de communautés dans les réseaux sociaux.
- Compression d’image (regrouper les pixels similaires).
- Analyse de documents ou de textes (thèmes cachés).
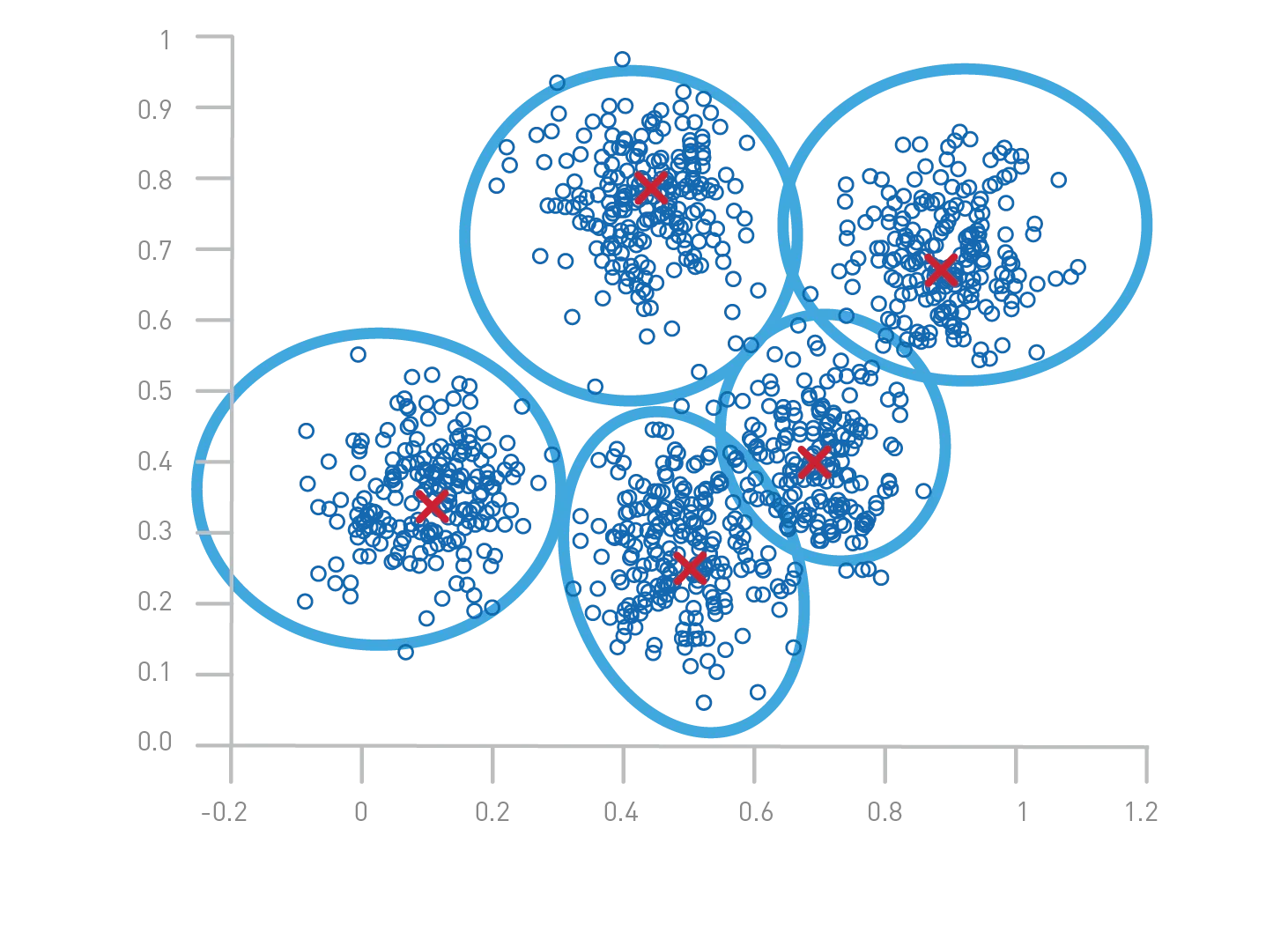
Illustration du clustering K-Means
Explication de l'image
- Points colorés : Chaque point représente une donnée. Les couleurs indiquent le cluster auquel le point a été assigné.
- Centres des clusters : Les grandes croix rouges marquent les centres (centroïdes) calculés pour chaque cluster.
- Séparation : Les points sont regroupés en fonction de leur proximité avec ces centres, formant ainsi des groupes distincts.
Étapes du clustering K-Means
- Initialisation : Choisir aléatoirement k centres (ici, 3).
- Assignation : Attribuer chaque point au centre le plus proche.
- Mise à jour : Recalculer les centres en prenant la moyenne des points de chaque cluster.
- Répétition : Répéter les étapes 2 et 3 jusqu'à convergence (les centres ne changent plus significativement).
Applications typiques
- Segmentation de clients : Identifier des groupes de clients aux comportements similaires.
- Analyse d'images : Regrouper des pixels pour segmenter une image.
- Biologie : Classifier des espèces ou des cellules selon leurs caractéristiques.
📌 À retenir
- C’est non supervisé : pas de "bonnes réponses" connues à l’avance.
- Le succès dépend souvent de la qualité des données, de la distance choisie, et du bon choix de l’algorithme.
- Un bon clustering doit produire des groupes cohérents en interne et distincts entre eux.
Réduction de dimensionnalité : simplifier sans perdre l’essence
La réduction de dimensionnalité est une technique d’apprentissage non supervisé utilisée pour simplifier les données complexes, tout en préservant leur structure essentielle. Elle est particulièrement utile lorsque les données ont beaucoup de variables (dimensions), ce qui rend difficile leur visualisation, leur traitement ou leur interprétation.
🎯 Objectif
Réduire le nombre de variables (ou caractéristiques) tout en :
- Minimisant la perte d'information ;
- Éliminant le bruit ou la redondance ;
- Facilitant la visualisation (souvent en 2D ou 3D) ;
- Améliorant l'efficacité des algorithmes comme le clustering.
⚙️ Méthodes principales
1. ACP (Analyse en Composantes Principales ou PCA - Principal Component Analysis)
- Transforme les variables initiales en un nouvel espace de variables appelées composantes principales, qui sont orthogonales (non corrélées).
- Les premières composantes capturent le maximum de variance possible des données.
- Utilisée pour visualiser les données en 2D/3D tout en gardant l’essentiel de la structure.
Avantages : rapide, simple, interprétable.
Inconvénient : suppose que les données sont linéaires.
2. t-SNE (t-distributed Stochastic Neighbor Embedding)
- Technique non linéaire qui préserve la proximité locale entre les points.
- Excellente pour visualiser des clusters cachés dans les données.
Avantages : très bon pour visualiser des données complexes.
Inconvénients : plus lent, non interprétable, non réutilisable pour de nouvelles données.
3. UMAP (Uniform Manifold Approximation and Projection)
- Alternative récente à t-SNE, plus rapide, tout en conservant la structure globale et locale des données.
- Utile pour la visualisation et le prétraitement avant clustering.
Avantages : plus rapide que t-SNE, bon équilibre entre local et global.
Inconvénients : plus complexe à paramétrer.
🧠 Exemple pratique
Vous avez un dataset avec 100 variables pour décrire chaque individu (âge, revenus, scores, etc.).
C’est illisible et peu exploitable visuellement.
Mais avec PCA, vous pouvez réduire ça à 2 ou 3 dimensions principales tout en conservant 80–90 % de l’information → vous pouvez ensuite appliquer un clustering ou visualiser les groupes avec des couleurs.
📌 En résumé

Détection d’anomalies : repérer l’inhabituel
La détection d’anomalies (ou détection de valeurs aberrantes) en apprentissage non supervisé consiste à identifier des données qui dévient fortement du comportement global du jeu de données, sans qu’on sache à l’avance ce qu’est une "anomalie".
C’est une tâche cruciale dans de nombreux domaines où les données anormales peuvent indiquer des problèmes, des fraudes, ou des événements rares à surveiller.
🎯 Objectif
Isoler les points qui ne ressemblent pas à la majorité des autres.
Dans un ensemble de données non étiquetées, l’algorithme apprend la structure normale, puis détecte les cas atypiques.
⚙️ Méthodes principales
1. Isolation Forest
- Basée sur l’idée que les anomalies sont plus faciles à isoler que les points normaux.
- Crée des arbres de partition aléatoires pour diviser les données : les anomalies sont isolées en peu de divisions.
Avantages : Rapide, efficace même pour de gros jeux de données.
Inconvénients : Moins interprétable.
2. One-Class SVM
- Modèle dérivé des SVM qui apprend la frontière de la classe normale.
- Tout point trop éloigné de cette frontière est considéré comme anormal.
Avantages : bon pour des jeux de données à faible dimension.
Inconvénients : sensible aux paramètres et à l’échelle des données.
3. Méthodes basées sur la densité (ex : LOF – Local Outlier Factor)
- Compare la densité locale autour de chaque point avec celle de ses voisins.
- Un point est anormal s’il est beaucoup moins dense que ses voisins.
Avantages : détecte les anomalies contextuelles.
Inconvénients : moins adapté aux très grandes dimensions.
4. Autoencoders (deep learning)
- Réseau de neurones entraîné à reconstruire les données normales.
- Si une donnée est mal reconstruite → elle est probablement anormale.
Avantages : très puissant sur des données complexes (images, séries temporelles).
Inconvénients : besoin d’un certain volume de données et de tuning.
🧠 Applications
- Détection de fraude (carte bancaire, assurance)
- Surveillance de machines industrielles (maintenance prédictive)
- Détection d’intrusions en cybersécurité
- Analyse de santé (signaux vitaux inhabituels)
📌 En résumé

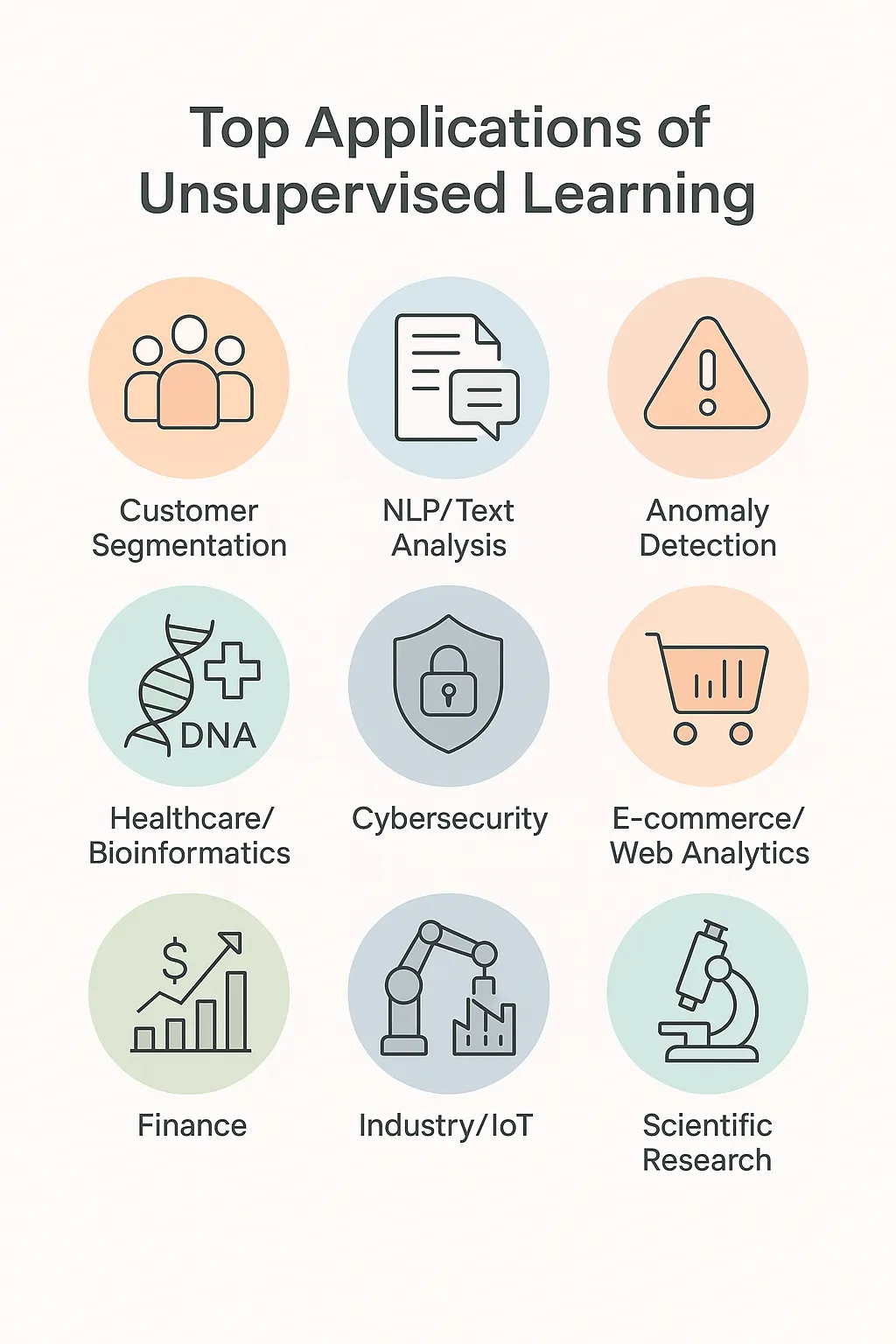
Applications concrètes de l’apprentissage non supervisé
Le potentiel de l’apprentissage non supervisé s’illustre dans des domaines variés :
- Segmentation client : distinguer des groupes d’utilisateurs aux comportements d’achat similaires.
- Analyse de comportements : comprendre les parcours utilisateurs sans labellisation.
- Systèmes de recommandation : suggérer des contenus basés sur la similarité implicite entre utilisateurs.
- Détection de fraudes : repérer des transactions financières atypiques.
- Diagnostic médical : découvrir des sous-types de maladies dans des bases de données biomédicales.
- Exploration scientifique : cartographier des données complexes en biologie ou en astronomie.
Pourquoi l’apprentissage non supervisé est-il de plus en plus crucial ?
Face à l’énorme croissance des données non structurées, l’apprentissage non supervisé devient incontournable pour :
- Gagner du temps et réduire la dépendance à l’annotation humaine.
- Découvrir des patterns invisibles aux analystes.
- Faciliter l’analyse de données massives et complexes.
De plus, il alimente aujourd’hui des avancées majeures en intelligence artificielle : modèles auto-supervisés, représentations latentes dans les réseaux de neurones, techniques de pré-entraînement pour le machine learning moderne.
Conclusion
L’apprentissage non supervisé ouvre une nouvelle frontière pour l’analyse de données : il permet de naviguer dans l’inconnu, d’explorer l’invisible et d’optimiser la compréhension du monde numérique.
Alors que le volume des données explose, maîtriser ces techniques devient un levier stratégique dans tous les secteurs.
À votre avis, comment pourrions-nous rendre l’apprentissage non supervisé plus interprétable et accessible ?
À lire également











Plongez dans l'IA avec nos ressources approfondies.
.webp)

