
Uczenie się przez wzmocnienie: klucz do autonomicznej sztucznej inteligencji
Wprowadzenie: W kierunku inteligentnej autonomii
Sztuczna inteligencja (AI) nieustannie przesuwa granice tego, co potrafią osiągnąć maszyny. Chociaż klasyczne uczenie maszynowe, zarówno nadzorowane, jak i nienadzorowane, pozwoliło na osiągnięcie znacznego postępu, obecnie uwagę naukowców, przedsiębiorstw, nauczycieli i osób zainteresowanych przyciąga nowa dziedzina: uczenie się przez wzmocnienie. To rewolucyjne podejście stawia agenta w centrum akcji, konfrontując go z dynamicznym środowiskiem, w którym uczy się on metodą prób i błędów, dokładnie tak jak człowiek odkrywający świat.
Od robotyki i sztucznej inteligencji, przez gry wideo i edukację, aż po finanse – uczenie się przez wzmocnienie staje się filarem współczesnej sztucznej inteligencji, a jego potencjał wydaje się być wciąż daleki od pełnego wykorzystania.
Czym jest uczenie się przez wzmocnienie?
Uczenie się przez wzmocnienie (ang. reinforcement learning, RL) to dziedzina uczenia maszynowego, w której inteligentny agent uczy się podejmować decyzje poprzez interakcję z otoczeniem. W przeciwieństwie do uczenia nadzorowanego, gdzie algorytm kieruje się przykładami opatrzonymi etykietami, w tym przypadku agent samodzielnie odkrywa, jak należy postępować, aby zmaksymalizować nagrodę.
Zasada jest prosta, ale skuteczna: po każdym podjętym działaniu agent otrzymuje informację zwrotną od otoczenia w postaci nagrody (pozytywnej lub negatywnej). Jego celem jest maksymalizacja łącznej liczby nagród w perspektywie długoterminowej poprzez stopniowe udoskonalanie strategii działania, zwanych politykami.
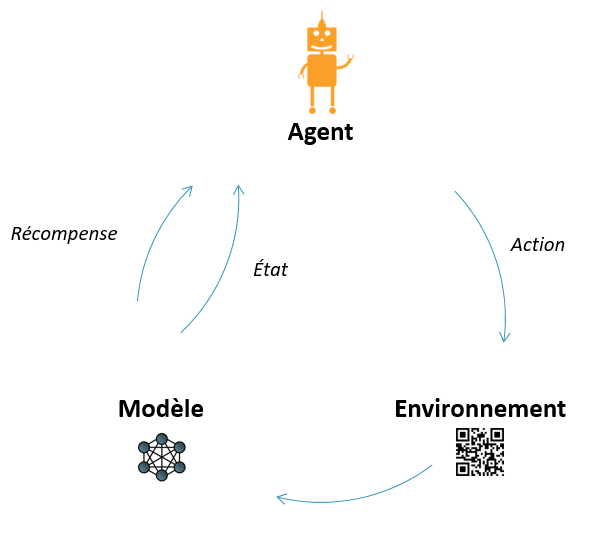
Jak działa uczenie się przez wzmocnienie?
Zagłębmy się w szczegóły tego fascynującego procesu uczenia się:
1. Funkcjonariusz
Agent to podmiot, który podejmuje działania. Może to być robot, oprogramowanie, a nawet postać z gry wideo. Jego celem jest nauczenie się, jak osiągnąć zamierzony cel w swoim otoczeniu.
2. Środowisko
Środowisko to wszystko, co otacza agenta. Dostarcza ono informacji o aktualnym stanie (zwanym stanem) i reaguje na działania agenta, generując nowe stany i nagrody.
3. Nagrody
Nagroda to sygnał cyfrowy wskazujący na jakość danego działania w określonej sytuacji. Nagroda pozytywna zachęca do powtórzenia działania, natomiast nagroda negatywna skłania do unikania takiego zachowania.
4. Polityka
Polityka (lub strategia) to strategia przyjęta przez agenta w celu wyboru działań w zależności od aktualnego stanu. Może być ona na początku stała, ale często jest z czasem optymalizowana.
5. Poszukiwanie i wydobycie
Funkcjonariusz musi nieustannie balansować między dwoma postawami:
- Eksploracja: wypróbowywanie nowych działań w celu odkrycia ich skutków.
- Wykorzystanie: stosowanie najlepszych znanych strategii w celu maksymalizacji zysków.
Znalezienie równowagi między odkrywaniem a wykorzystaniem wiedzy ma zasadnicze znaczenie dla skutecznego uczenia się.
6. Iteracje i ciągłe doskonalenie
Uczenie się odbywa się poprzez kolejne iteracje: przy każdej interakcji agent aktualizuje swoje rozumienie świata i udoskonala swoją strategię działania.
Klasycznym algorytmem służącym do realizacji tego procesu uczenia się jest Q-learning. Algorytm ten tworzy tabelę Q, w której każdej parze (stan, działanie) przypisana jest szacowana wartość jakości, a następnie aktualizuje te wartości na podstawie uzyskanych wyników.
Podstawowe równanie uczenia się typu Q:
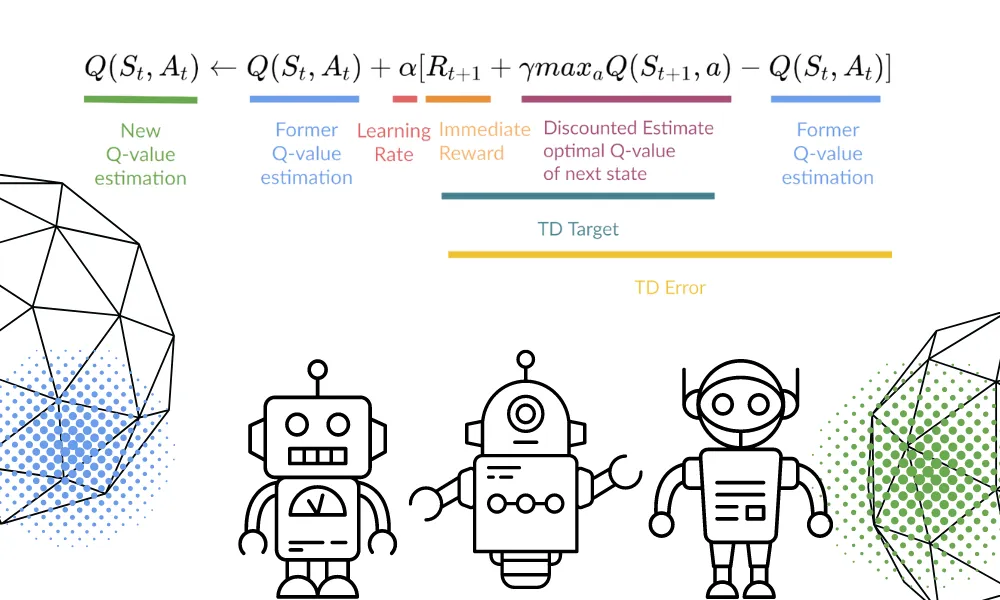
Przykłady konkretnych zastosowań
Uczenie się przez wzmocnienie nie ogranicza się do teorii: już teraz kształtuje naszą codzienność.
1. Robotyka i sztuczna inteligencja
W robotyce opartej na sztucznej inteligencji robot może nauczyć się chodzić, chwytać przedmioty lub omijać przeszkody bez konieczności wyraźnego programowania. Na przykład AlphAI firmy Learning Robots umożliwia robotom edukacyjnym naukę autonomicznych zachowań, które można obserwować w czasie rzeczywistym.
2. Gry wideo
Inteligentne systemy pokonały mistrzów w skomplikowanych grach, takich jak Go (AlphaGo firmy DeepMind) czy StarCraft II. Wykorzystują one miliony iteracji, aby odkryć optymalne strategie.
3. Finanse
W branży finansowej algorytmy uczenia się przez wzmocnienie optymalizują portfele inwestycyjne, dynamicznie dostosowując strategie kupna i sprzedaży do zmian na rynku.
4. Transport autonomiczny
Pojazdy autonomiczne również wykorzystują te algorytmy do podejmowania optymalnych decyzji dotyczących jazdy w złożonych i nieprzewidywalnych warunkach.
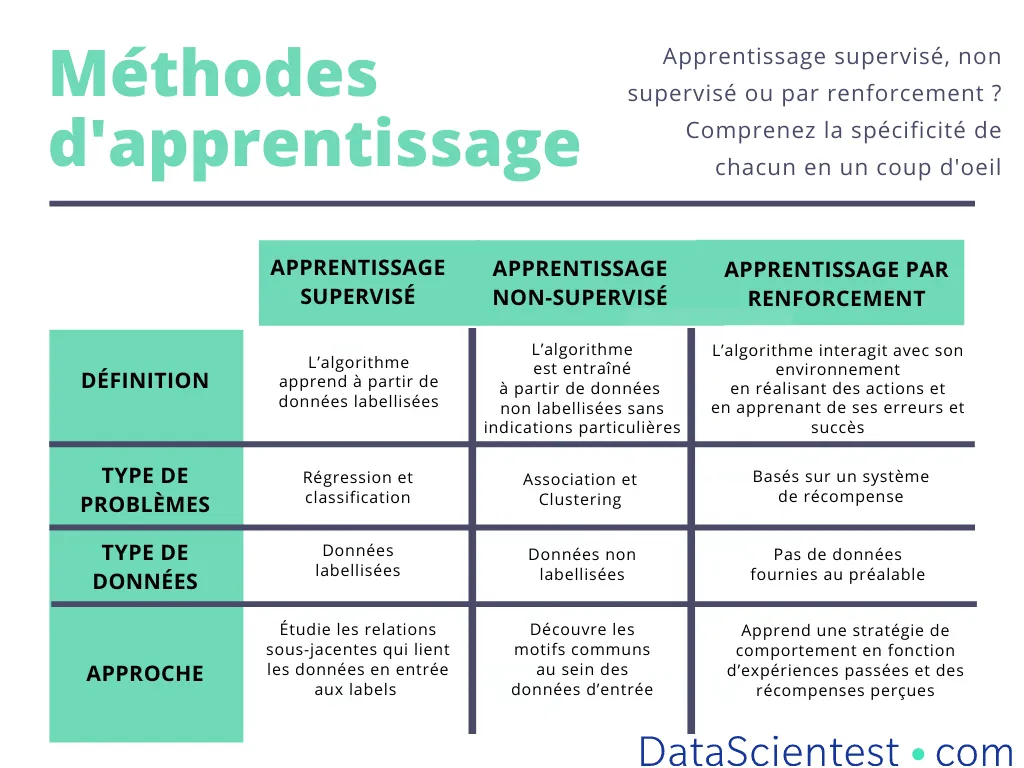
Porównanie z uczeniem nadzorowanym i nienadzorowanym
Uczenie nadzorowane: algorytm uczy się na podstawie danych opatrzonych etykietami (znanych przykładów/odpowiedzi). Przykład: klasyfikowanie zdjęć kotów i psów.
Uczenie się bez nadzoru: algorytm próbuje odkryć ukryte struktury bez etykiet (takie jak grupy).
Uczenie się przez wzmocnienie: algorytm uczy się działać w danym środowisku, otrzymując nagrody z opóźnieniem.
Każde z tych podejść ma swoje zastosowanie. Uczenie się przez wzmocnienie sprawdza się szczególnie w sytuacjach wymagających sekwencyjnego i adaptacyjnego podejmowania decyzji.
Rosnące znaczenie i przyszłość uczenia się przez wzmocnienie
Wraz z rozwojem sztucznej inteligencji i głębokich sieci neuronowych (deep reinforcement learning) coraz większego znaczenia nabiera uczenie się przez wzmocnienie. Otwiera ono drogę do proaktywnych systemów, które są w stanie nie tylko przetwarzać dane, ale także działać w świecie rzeczywistym w sposób autonomiczny i zoptymalizowany.
W najbliższych latach spodziewamy się pojawienia się jeszcze bardziej ambitnych zastosowań w tak różnorodnych sektorach, jak medycyna spersonalizowana, inteligentne zarządzanie energią czy edukacja.
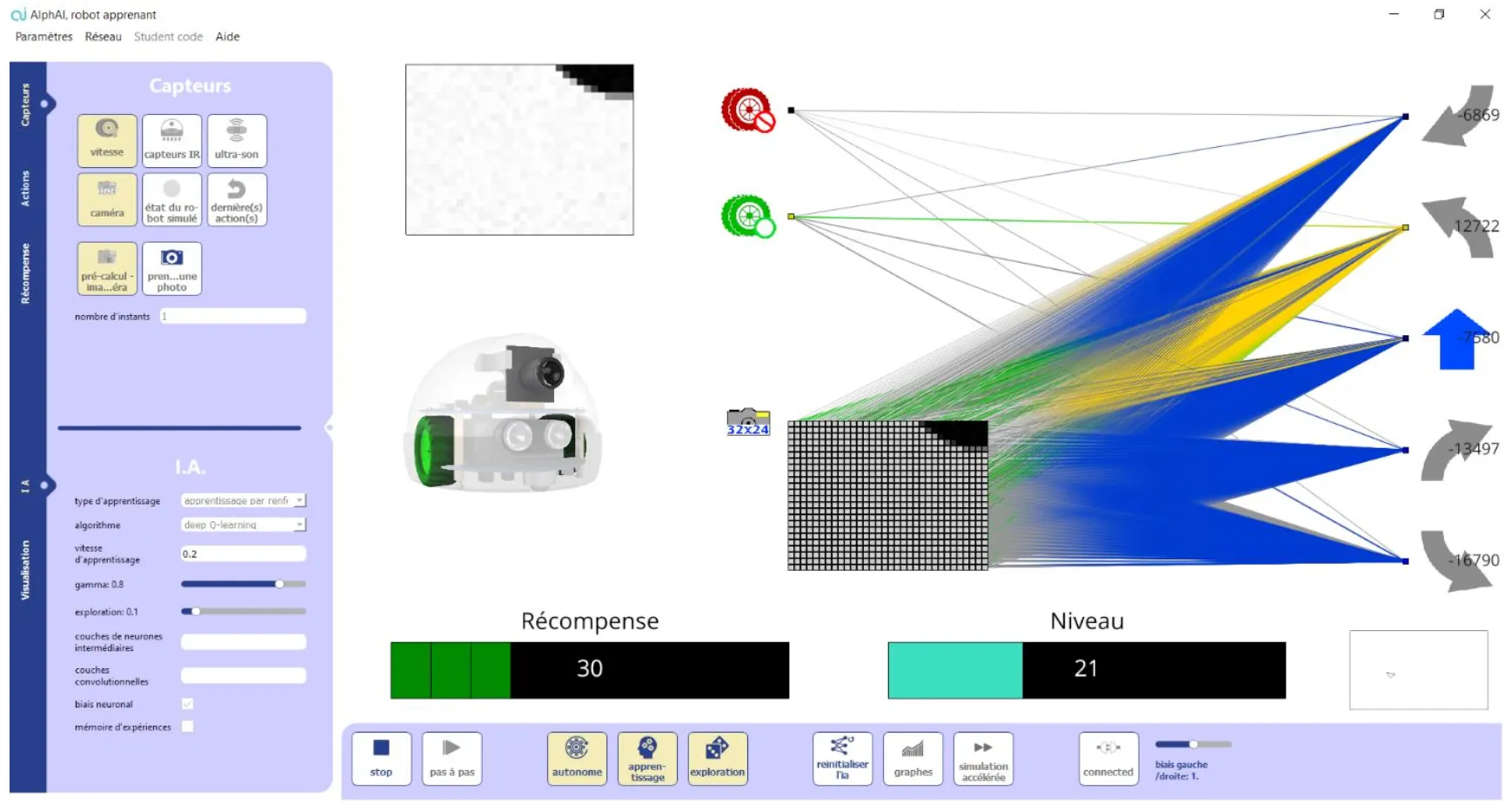
Learning Robots i AlphAI: ułatwianie dostępu do uczenia się przez wzmocnienie
Poznanie niuansów uczenia się przez wzmocnienie może wydawać się skomplikowane. Dlatego firma Learning Robots oferuje AlphAI – wyjątkowe rozwiązanie edukacyjne.
Dzięki AlphAI nauczyciele, uczniowie i specjaliści mogą:
- Zobacz na żywo, jak działa uczenie się przez wzmocnienie.
- Modyfikowanie parametrów algorytmów uczenia maszynowego.
- Praktyczne zrozumienie pojęć eksploracji i eksploatacji, nagrody oraz polityki.
- Programowanie i sterowanie prawdziwymi robotami edukacyjnymi.
AlphAI jest obecnie doskonałym narzędziem do tworzenia innowacyjnych rozwiązań w dziedzinie sztucznej inteligencji w edukacji, łączącym teorię z praktyką i wyjaśniającym skomplikowane zagadnienia.
Dowiedz się, jak AlphAI sprawia, że kluczowa dziedzina sztucznej inteligencji staje się przystępna i przyjemna, na stronie rozwiązanie.
Wniosek: Uczenie się przez wzmocnienie – siła napędowa autonomicznej sztucznej inteligencji
Uczenie się przez wzmocnienie radykalnie zmienia sposób, w jaki maszyny uczą się współdziałać ze swoim otoczeniem. Od robotyki opartej na sztucznej inteligencji po gry wideo, od rynków finansowych po samochody autonomiczne – staje się ono nieodzownym filarem współczesnej sztucznej inteligencji.
Dzięki takim pojęciom jak nagroda, polityka oraz równowaga między eksploracją a eksploatacją umożliwia tworzenie autonomicznych agentów zdolnych do optymalizacji swoich decyzji w złożonych kontekstach.
Masz ochotę przejść od teorii do praktyki?
Aby w praktyce zapoznać się z uczeniem się przez wzmocnienie i zobaczyć te fascynujące koncepcje w akcji, zapoznaj się z naszym rozwiązaniem AlphAI.
Warto przeczytać











Zanurz się w świecie sztucznej inteligencji dzięki naszym szczegółowym materiałom.
.webp)

