
Unüberwachtes Lernen: Das Unsichtbare enthüllen im Zeitalter der künstlichen Intelligenz
Einführung
Im Zeitalter von Big Data und künstlicher Intelligenz produzieren wir jeden Tag phänomenale Datenmassen: Texte, Bilder, Videos, Transaktionen, digitale Signale. Doch die meisten dieser Daten haben keine Etiketten, die ihren Inhalt erklären.
Wie kann man ohne intensives menschliches Eingreifen Werte extrahieren?
Das unüberwachte Lernen ist die Antwort auf diese Herausforderung: Indem es automatisch verborgene Strukturen und Muster aufspürt, revolutioniert es die Datenanalyse in so unterschiedlichen Bereichen wie Gesundheit, Finanzen oder Marketing.
Lassen Sie uns gemeinsam herausfinden, warum diese Säule des maschinellen Lernens unverzichtbar geworden ist.
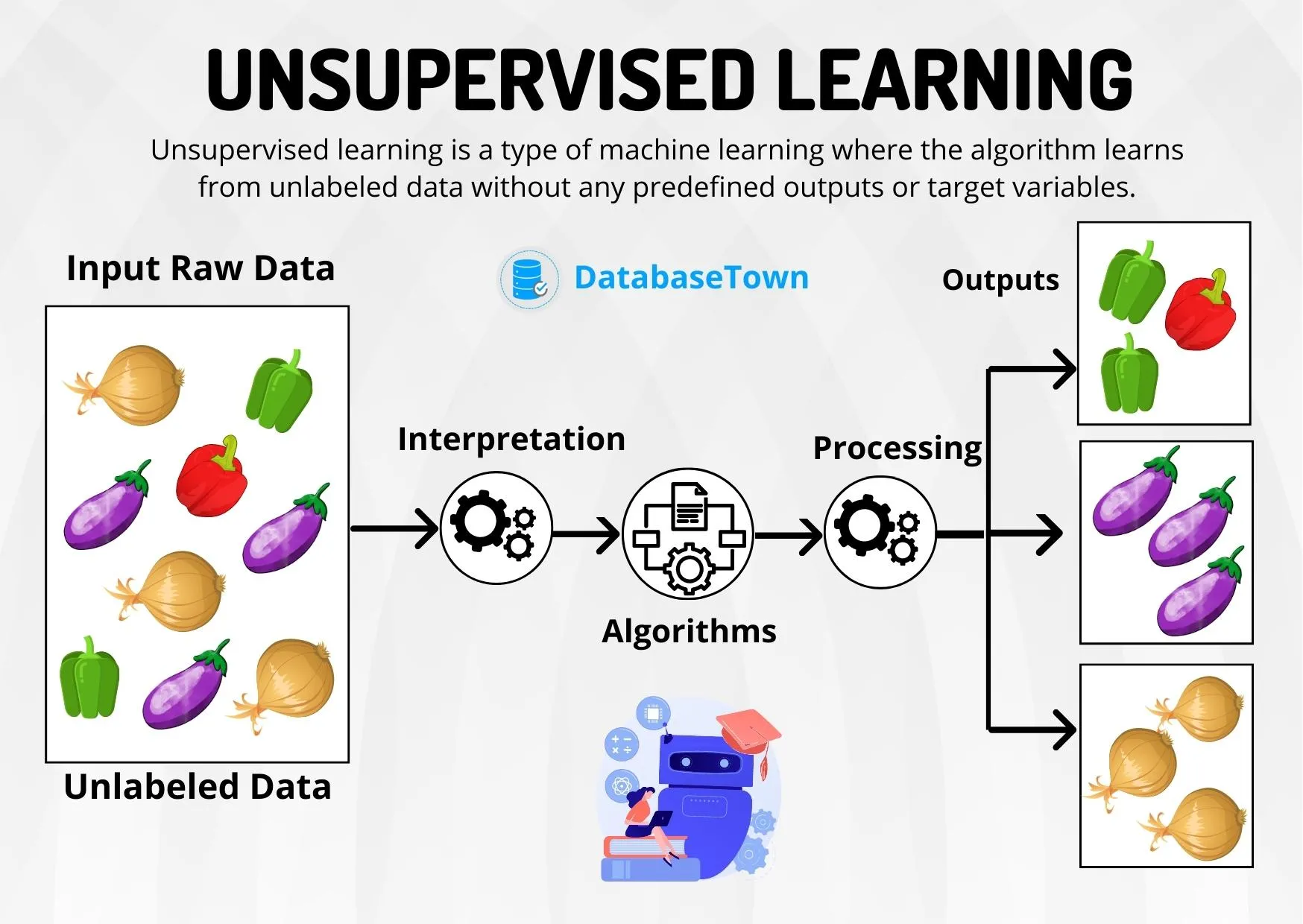
Was ist unüberwachtes Lernen?
Unüberwachtes Lernen bezeichnet eine Kategorie des maschinellen Lernens, bei der Algorithmen Muster in nicht beschrifteten Daten erkennen müssen, d. h. ohne vorherige Angabe ihrer Bedeutung.
Im Gegensatz zum überwachten Lernen, bei dem jede Eingabe mit einer bestimmten Ausgabe verknüpft wird, zielt das unüberwachte Lernen darauf ab, inhärente Strukturen in den Daten zu entdecken.
Ziel: Daten zu organisieren, zu segmentieren oder zu vereinfachen, ohne vorheriges Wissen.
Wie funktioniert unüberwachtes Lernen?
Das unüberwachte Lernen beruht hauptsächlich auf drei Haupttechniken:
Clustering: Zusammenfassen ähnlicher Daten
Clustering (oder Gruppierung) ist eine zentrale Technik im nicht überwachten Lernen, bei der ähnliche Daten automatisch ohne vorherige Beschriftung zusammengefasst werden. Ziel ist es, eine Struktur oder verborgene Muster in den Daten zu entdecken.
🔍 Grundprinzip
Der Clustering-Algorithmus weist jedem Datensatz eine Gruppe (oder ein Cluster) zu, je nachdem, wie ähnlich er den anderen Daten ist. Dieses Kriterium der Ähnlichkeit hängt oft von einem Entfernungsmaß (wie der euklidischen Distanz ) ab.
Wenn du einem Algorithmus z. B. Punkte gibst, die Kunden darstellen (mit Merkmalen wie Alter und Ausgaben), kann er diese in typische Profile gruppieren (junge, verschwenderische Menschen, sparsame Rentner usw.), ohne vorher zu wissen, wie viele Typen es gibt und welche Merkmale diese haben.
⚙️ Beliebte Clustering-Algorithmen
- K-Means
- Teilt die Daten in k Gruppen auf, indem der Abstand zwischen den Punkten und dem Zentrum des Clusters minimiert wird.
- Erfordert, dass k im Voraus festgelegt wird.
- Einfach, schnell, aber anfällig für Ausreißer.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Gruppiert die dichten Punkte zusammen.
- Identifiziert Ausreißer (Rauschen) auf natürliche Weise.
- Erfordert keine Definition von k, sondern von Parametern wie der Epsilon-Distanz.
- Effektiv bei komplexen Formen.
- Hierarchisches Clustering
- Erstellt eine Hierarchie von Clustern (eine Art Baum oder Dendrogramm).
- Erfordert nicht immer die Festlegung von k.
- Kann agglomerativ (von unten nach oben) oder divisiv (von oben nach unten) sein.
🧠 Anwendungen
- Kundensegmentierung im Marketing.
- Erkennung von Gemeinschaften in sozialen Netzwerken.
- Bildkomprimierung (Gruppierung ähnlicher Pixel).
- Analyse von Dokumenten oder Texten (verborgene Themen).
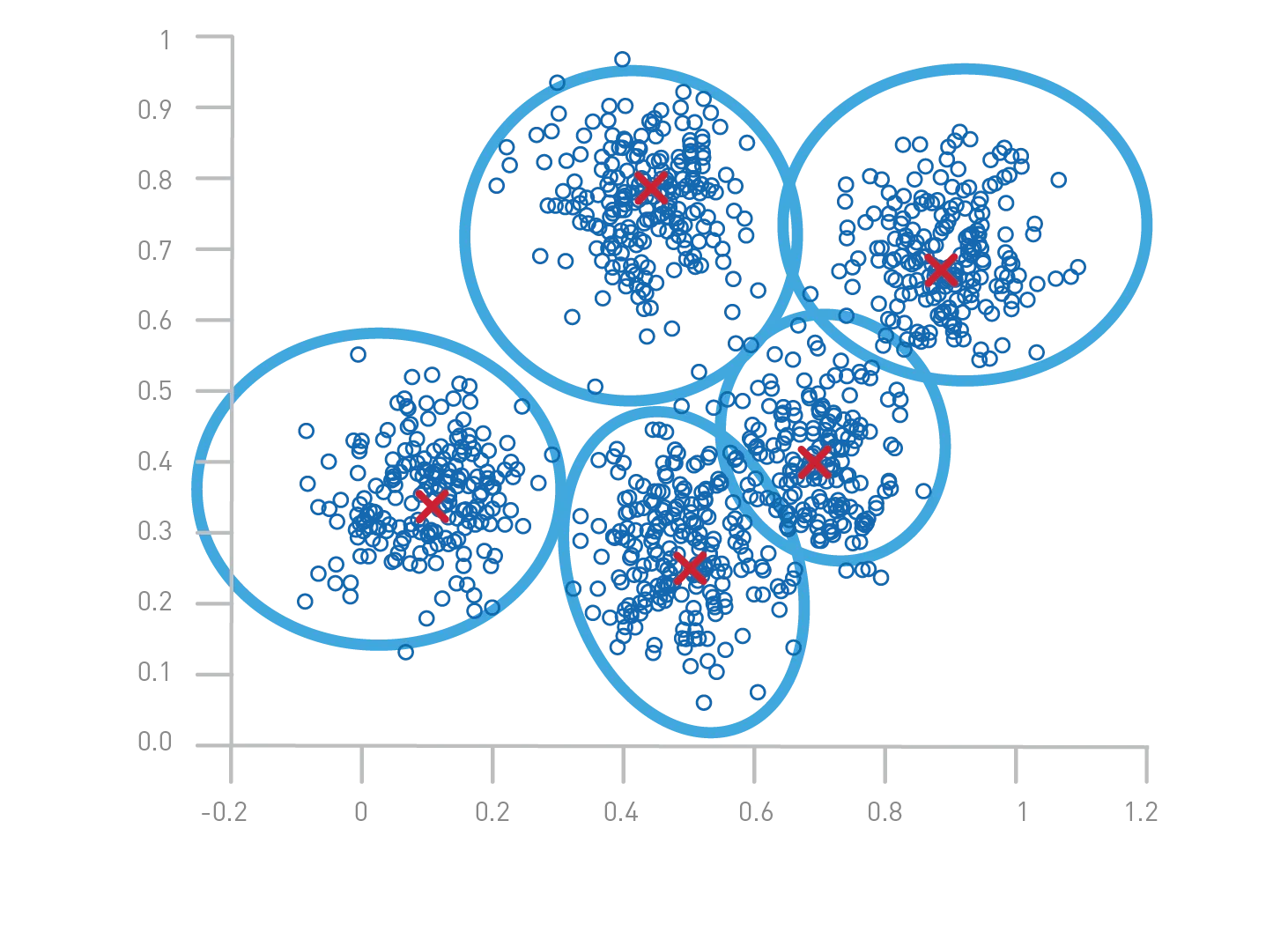
Illustration des K-Means-Clustering
Erklärung des Bildes
- Farbige Punkte: Jeder Punkt repräsentiert einen Datensatz. Die Farben zeigen den Cluster an, dem der Punkt zugewiesen wurde.
- Clusterzentren: Die großen roten Kreuze markieren die Zentren (Zentroide), die für jeden Cluster berechnet wurden.
- Trennung: Die Punkte werden entsprechend ihrer Nähe zu diesen Zentren gruppiert und bilden so separate Gruppen.
Schritte des K-Means-Clustering
- Initialisierung: Wählen Sie k Zentren (hier 3) zufällig aus.
- Zuweisung: Weisen Sie jeden Punkt dem nächstgelegenen Zentrum zu.
- Aktualisiert: Berechnen Sie die Zentren neu, indem Sie den Durchschnitt der Punkte jedes Clusters nehmen.
- Wiederholung: Wiederhole die Schritte 2 und 3 bis zur Konvergenz (die Zentren verändern sich nicht mehr signifikant).
Typische Anwendungen
- Segmentierung von Kunden: Ermittlung von Gruppen von Kunden mit ähnlichem Verhalten.
- Bildanalyse: Gruppieren von Pixeln, um ein Bild zu segmentieren.
- Biologie: Arten oder Zellen nach ihren Merkmalen klassifizieren.
📌 Zu beachten
- Es ist unbeaufsichtigt: keine "richtigen Antworten", die im Voraus bekannt sind.
- Der Erfolg hängt oft von der Qualität der Daten, der gewählten Distanz und der richtigen Wahl des Algorithmus ab.
- Ein gutes Clustering sollte Gruppen erzeugen, die intern kohärent und untereinander unterscheidbar sind.
Reduzierung der Dimensionalität: Vereinfachen, ohne die Essenz zu verlieren
Die Dimensionsreduktion ist eine Technik desnicht überwachten Lernens, die verwendet wird, um komplexe Daten zu vereinfachen, während ihre wesentliche Struktur erhalten bleibt. Sie ist besonders nützlich, wenn die Daten viele Variablen (Dimensionen) haben, was es schwierig macht, sie zu visualisieren, zu verarbeiten oder zu interpretieren.
🎯 Ziel
Die Anzahl der Variablen (oder Merkmale) reduzieren und dabei :
- Minimierung des Informationsverlusts;
- Eliminierung von Lärm oder Redundanz;
- Erleichtern die Visualisierung (oft in 2D oder 3D);
- Verbessert die Effizienz von Algorithmen wie Clustering.
⚙️ Hauptmethoden
1. PCA (Principal Component Analysis) (Hauptkomponentenanalyse oder PCA - Hauptkomponentenanalyse)
- Wandelt die ursprünglichen Variablen in einen neuen Raum von Variablen um, die Hauptkomponenten genannt werden und orthogonal (unkorreliert) sind.
- Die ersten Komponenten erfassen die maximal mögliche Varianz der Daten.
- Wird verwendet, um Daten in 2D/3D zu visualisieren und dabei das Wesentliche der Struktur beizubehalten.
Vorteile: schnell, einfach, interpretierbar.
Nachteil: Setzt voraus, dass die Daten linear sind.
2. t-SNE (t-distributed Stochastic Neighbor Embedding)
- Nichtlineare Technik, bei der die lokale Nähe zwischen den Punkten erhalten bleibt.
- Hervorragend geeignet, um verborgene Cluster in den Daten zu visualisieren.
Vorteile: Sehr gut geeignet, um komplexe Daten zu visualisieren.
Nachteile: langsamer, nicht interpretierbar, nicht für neue Daten wiederverwendbar.
3. UMAP (Uniform Manifold Approximation and Projection)
- Neuere Alternative zu t-SNE, schneller, unter Beibehaltung der globalen und lokalen Datenstruktur.
- Nützlich für die Visualisierung und Vorverarbeitung vor dem Clustering.
Vorteile: schneller als t-SNE, gutes Gleichgewicht zwischen lokal und global.
Nachteile: Komplizierter einzurichten.
🧠 Praktisches Beispiel
Sie haben ein Dataset mit 100 Variablen, um jede Person zu beschreiben (Alter, Einkommen, Punktzahl, etc.).
Es ist unleserlich und visuell kaum verwertbar.
Aber mit PCA können Sie das auf 2 oder 3 Hauptdimensionen reduzieren und dabei 80-90 % der Information behalten → Sie können dann ein Clustering anwenden oder die Gruppen mit Farben visualisieren.
📌 Zusammengefasst

Anomalieerkennung: Ungewöhnliches aufspüren
Bei der Erkennung von Anomalien (oder Ausreißererkennung) beim unüberwachten Lernen geht es darum, Daten zu identifizieren , die stark vom Gesamtverhalten des Datensatzes abweichen, ohne dass man vorher weiß, was eine "Anomalie" ist.
Dies ist eine entscheidende Aufgabe in vielen Bereichen, in denen abnormale Daten auf Probleme, Betrug oder seltene Ereignisse hinweisen können, die es zu überwachen gilt.
🎯 Ziel
Isolieren Sie die Punkte, die nicht wie die Mehrheit der anderen aussehen.
In einem nicht gekennzeichneten Datensatz lernt der Algorithmus die Normalstruktur und erkennt dann atypische Fälle.
⚙️ Hauptmethoden
1. Isolation Wald
- Basiert auf der Idee, dass Anomalien leichter zu isolieren sind als normale Punkte.
- Erstellt zufällige Partitionsbäume, um die Daten zu teilen: Anomalien werden in wenigen Teilungen isoliert.
Vorteile: Schnell, effizient auch bei großen Datensätzen.
Nachteile: Weniger interpretierbar.
2. One-Class SVM
- Von SVMs abgeleitetes Modell, das die Grenze der normalen Klasse lernt.
- Jeder Punkt, der zu weit von dieser Grenze entfernt ist, wird als anormal betrachtet.
Vorteile: Gut für Datensätze mit geringer Dimension.
Nachteile: empfindlich gegenüber Parametern und Skalierung der Daten.
3. Dichtebasierte Methoden (z.B. LOF - Local Outlier Factor)
- Vergleicht die lokale Dichte um jeden Punkt mit der Dichte seiner Nachbarn.
- Ein Punkt ist abnormal, wenn er viel weniger dicht ist als seine Nachbarn.
Vorteile: Erkennt kontextabhängige Anomalien.
Nachteile: Weniger geeignet für sehr große Abmessungen.
4. Autoencoders (deep learning)
- Neuronales Netz, das darauf trainiert ist, normale Daten zu rekonstruieren.
- Wenn ein Datensatz schlecht rekonstruiert wird → ist er wahrscheinlich abnormal.
Vorteile: sehr leistungsstark bei komplexen Daten (Bilder, Zeitreihen).
Nachteile: Benötigt eine gewisse Menge an Daten und Tuning.
🧠 Anwendungen
- Betrugserkennung (Bankkarte, Versicherung)
- Überwachung von Industriemaschinen (vorausschauende Wartung)
- Erkennung von Eindringlingen in die Cybersicherheit
- Gesundheitsanalyse (ungewöhnliche Vitalsignale)
📌 Zusammengefasst

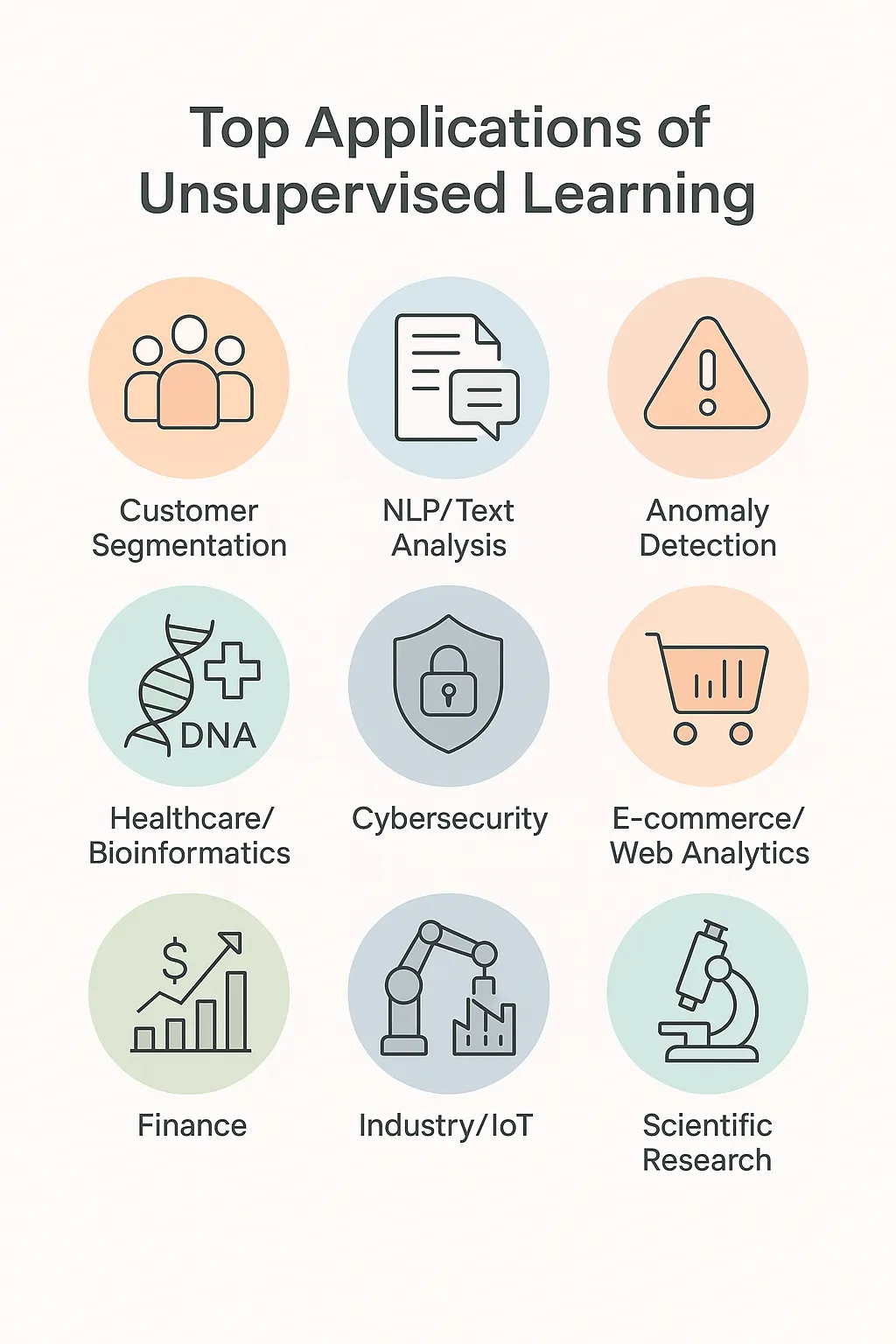
Konkrete Anwendungen des nicht überwachten Lernens
Das Potenzial des unüberwachten Lernens zeigt sich in vielen verschiedenen Bereichen:
- Kundensegmentierung: Unterscheidung von Nutzergruppen mit ähnlichem Kaufverhalten.
- Verhaltensanalyse: Verstehen der Benutzerwege ohne Kennzeichnung.
- Empfehlungssysteme: Vorschlagen von Inhalten auf der Grundlage der impliziten Ähnlichkeit zwischen Nutzern.
- Betrugserkennung: Aufspüren von atypischen Finanztransaktionen.
- Medizinische Diagnostik: Entdecken Sie Unterarten von Krankheiten in biomedizinischen Datenbanken.
- Wissenschaftliche Erkundung: Kartierung komplexer Daten in der Biologie oder Astronomie.
Warum ist unüberwachtes Lernen zunehmend entscheidend?
Angesichts des enormen Wachstums unstrukturierter Daten wird unüberwachtes Lernen unumgänglich, um :
- Zeit sparen und die Abhängigkeit von menschlichen Anmerkungen verringern.
- Entdecken Sie Patterns, die für Analysten unsichtbar sind.
- Erleichtern Sie die Analyse großer und komplexer Datenmengen.
Darüber hinaus befeuert es heute wichtige Fortschritte in der künstlichen Intelligenz: selbstüberwachende Modelle, latente Repräsentationen in neuronalen Netzen, Pre-Training-Techniken für das moderne Machine Learning.
Schlussfolgerung
Das unüberwachte Lernen eröffnet eine neue Grenze für die Datenanalyse: Es ermöglicht uns, im Unbekannten zu navigieren, das Unsichtbare zu erforschen und das Verständnis der digitalen Welt zu optimieren.
Da das Datenvolumen explodiert, wird die Beherrschung dieser Techniken zu einem strategischen Hebel in allen Branchen.
Wie könnten wir Ihrer Meinung nach unbeaufsichtigtes Lernen besser interpretierbar und zugänglich machen?
Auch zu lesen











Tauchen Sie mit unseren vertiefenden Ressourcen in die KI ein.
.webp)

