Discover our
resources



Equipment:
- 1 robot minimum
- 1 computer/robot
- Flat environment
Settings :
- Supervised learning - Camera
Duration :
1h30 (2x45 min)
Age :
Ages 8 and up
Recommended for hands-on learning
Teach your robot to react to specific situations!
This activity will teach you how to set up the AlphAI software and its neural network to run Mbot in a simple environment.
Hardware
A computer with a webcam.
Post-it notes in 4 different colors or small sheets of paper with large colored arrows drawn on them. Examples below.
Configuration
The software can be configured manually or automatically.
To configure it automatically :
Parameters > Load example parameters > Supervised learning - Obstacle avoidance (simple)
Configuration can also be carried out manually by following the instructions opposite.
- Sensors > 21*16 camera

- Actions > Forward , Turn , Reverse , Stop
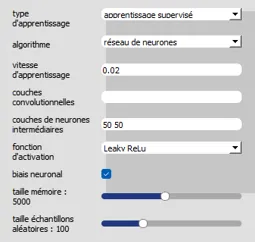
- AI > Learning type "Supervised learning", Algorithm" neural network ", Learning speed" 0.02 ",Convolutional layers:empty,Intermediate neural layers: 50 50.
Level 1
Color recognition
For each action, go forward, backward, turn left or right:
- Choose a color to assign to this action.
- Place the Post-it in this color in front of the computer camera.
- Press the corresponding action icon (or use the keyboard). The robot performs the requested action and memorizes the association of this image with this action.

=Advance

=Reculer

=turnleft

=turn right
Stopping
Now you have to teach the robot to stop when it doesn't see any colored post-it notes in the image.
Click on the stop action (black square) when no post-it note is visible on the camera. The robot doesn't move, but memorizes the association of this image with the stop action.
You can check that the association has been memorized by consulting the size of the experience memory at the top of the screen.

=Stop
Now that the robot's training is complete, simply activate the autonomous mode by clicking on the corresponding button or pressing the space bar.
Take your colorful post-it notes and place them in front of the camera to control the robot!

Understanding
How does the robot make decisions?
Deactivate stand-alone mode by clicking on the button or pressing the space bar.
Each pixel in the image is broken down into 3 colors: red, green and blue. We therefore see 3 monochrome versions of the image on the screen, which, when superimposed, produce the full-color image.
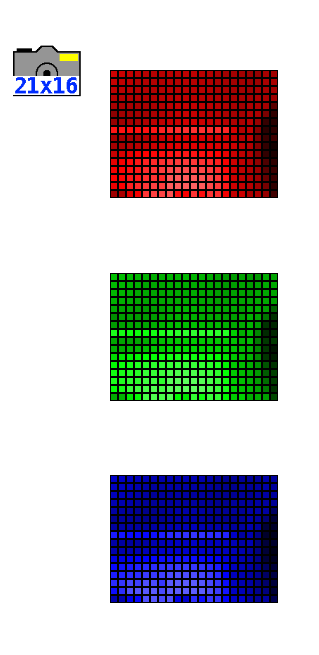
Please note: this is additive color synthesis, not to be confused with primary colors in painting! (Which correspond to a subtractive synthesis).
Each pixel of a monochrome image is associated with an input neuron, whose value is used to calculate the activation levels of successive layers, up to the output layer.
How does the camera detect colors?
The color of the post-it note influences the pixels. Indeed, a yellow color will be detected by the darkening of the corresponding area in the blue image. In fact, yellow is a superposition of red and green, but does not contain any blue.
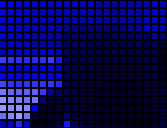
Blue channel for a yellow post-it note

For a blue post-it note
The principle is the same for the other two color channels. The camera will therefore differentiate between the colors present on the post-it notes, enabling the robot to make a decision.

Red channel for yellow post-it

For the blue post-it
When we hold a post-it note up to the camera, as shown in the photo below, we can see that the camera detects the colored area.
This affects the values of the input neurons, which will propagate this information to successive layers of neurons.

When the neural network is trained, the calculations it performs lead it to output the highest value for the action that best matches the data it has stored.
The choice to stop is based on the same principle. However, in this case there are no post-it notes! Instead, the neural network detects more specific details in the image (person, background, etc.).

The calculations result in the highest value being given to the stop action when these details are detected.
⚠️L The only sensor present in this activity is the computer's camera. This means that the robot has no way of knowing if there's an obstacle in front of it. It's entirely up to you to guide it to avoid a blockage, bump or fall.
Level 2
Moving with the hand
To move the robot by hand, you'll need to be more rigorous when training your mBot. This means that, for optimal training, you'll need to perform several learning points for each of your robot's actions.
When training, it's important to ensure that the background of the image (everything other than your hand) is sufficiently fixed: same framing, same lighting, same number of people present and in the same seats, etc. These rules must also be observed during the use phase! These rules must also be observed during the use phase!
Forward, backward, left turn, right turn
Place your hand in the foreground of the image.
Adapt the position of your hand to the action to be learned.
Record several examples for each action (e.g. 10 data points per action).

=Avancer

=Reculer

=Turnleft

= Turn right
Stopping
As in the previous section, we need to teach the robot to stop when it doesn't detect a hand in the foreground of the image.
=Stop
Now that the robot's training is complete, simply activate the autonomous mode by clicking on the corresponding button or pressing the space bar.
Place your hand in front of the camera as you did during training, and watch the robot's reactions!
Understanding
Camera operation is identical in both apprenticeships.
But this time, the neural network has to learn to detect the position of your hand in the image, rather than the color of a post-it note. This is a more complex task for a neural network, as there is no objective boundary between a central position and a position on the right, for example. The network will therefore have to determine for itself where to place the limits between the 4 possible positions.
What's more, there are many disruptive elements that can alter the network's decision-making. The network must learn that the size of your hand, its shape, the position of the fingers, its orientation, etc., are not important for decision-making: only the position of the hand must be taken into account. That's why you need to give several examples for each type of action.
The image background is also a major source of disturbance. That's why it's important to keep the background as fixed as possible.
This level will enable you to achieve a fluid result when moving the robot, and go hand in hand with a better understanding of how artificial intelligence works.
Duringtraining
During autonomy
=OK
The camera is in the same position and returns the same information for both phases. The robot focuses on my hand, not the background.
💡Atip: If you're doing this activity alone, make sure you can observe the robot without moving your head during training and autonomy.
Explicit bias
Today's AIs work by automatically learning from examples. These examples are called training data. The quality of the result obtained therefore depends first and foremost on the quality of the training data.
In machine learning, we seek to avoid the presence of two types of bias in the training data (i.e. errors, undesirable phenomena or, in general, deviations between the desired result and the result obtained).
The first type of bias is called explicit bias. It is a human error of classification when training the AI. Example: If the robot has been asked to move backwards when the camera sees the image below (for example, because the wrong key was inadvertently pressed).
+

(Reverse)
=Explicit bias
In this case, the neural network will have difficulty making a decision when the camera observes a similar image, because of this contradiction in its training data.
To eliminate this type of bias, all you have to do is remove these errors from the data.

Implicit bias
Implicit biases are more difficult to detect, as they are not objective errors, but rather a lack of diversity in the data, which is not sufficient to cover all the cases encountered during use.
Here's a simple rule to remember: when the AI is faced with a situation that is too different from all its training data, then the AI's choice in the face of that situation is unpredictable!
To avoid this, during training, particular care must be taken to generate a diversity of examples representative of the situations the AI is likely to encounter in use.
Training data


Image for analysis
What decision will the AI make?
How can the training data be improved to ensure that this decision is the right one? (hint: 4 examples should be used).