Entdecken Sie unsere Lehrmaterialien



Material :
- mindestens 1 Roboter
- 1 Computer/Roboter
- Flache Umgebung
Einstellungen :
- Überwachtes Lernen - Vermeidung von Hindernissen (komplex)
Dauer: 1,5 Stunden (2*45 min)
Alter: 8 Jahre und älter
Empfohlen zum Entdecken durch Manipulation
Bringen Sie Ihrem Roboter bei, auf bestimmte Situationen zu reagieren!
In dieser Aktivität lernen Sie, wie Sie die AlphAI-Software und das neuronale Netz einrichten, um mBot in einer einfachen Umgebung zu betreiben.
Material
Für die Durchführung dieser Aktivität müssen Sie eine kleine quadratische Arena zusammenbauen:
Wir empfehlen Ihnen, unsere individuelle Arena zu verwenden, die auf unserer Website oder bei unseren Händlern erhältlich ist.
Sie können auch Ihre eigene Arena errichten. Dazu benötigen Sie eine saubere, ebene Fläche (z. B. einen Tisch), die von Begrenzungen (z.B. aus Holz) umgeben ist, deren Farbe sich vom Boden unterscheidet und die stark genug sind, um den Roboter aufzuhalten.

Konfiguration
Die Software kann manuell oder automatisch konfiguriert werden.So konfigurieren Sie die Software automatisch:Einstellungen > Beispielparameter laden > Reinforcement Learning- Hindernisse vermeidenDie Konfiguration kann auch manuell erfolgen, indem Sie den nebenstehenden Anweisungen folgen.
- Sensoren > Ultraschall, Bewegungserkennung, zuletzt ausgeführte Aktion



- Aktionen > Vorwärts, Drehen, Rückwärts beim Drehen

- Belohnung > "Hindernis ausweichen".

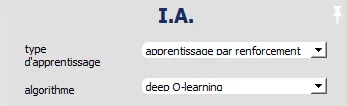
- KI > Lernart "Reinforcement Learning", Algorithmus" deep Q-Learning ",Intermediate Neuronal Layer: 300 100 50.

- Visualisierung > Wählen Sie: "Neuronales Netz", "Verbindungen", "Synaptische Aktivität".

Konzept
Für diese Aktivität gibt es keine Trainingsphase.
Beim Lernen durch Reinforcement Learning lernt der Roboter selbstständig durch Try and Error. Durch einfaches Drücken der Taste "Selbstständig" beginnt die Aktivität und lässt den Roboter selbstständig üben.

Sobald der Knopf gedrückt ist, muss man den Roboter nur noch beobachten und ihn selbstständig trainieren lassen.
Sie können auch sehen, dass das neuronale Netz viel imposanter ist und über mehrere Zwischenschichten verfügt. Die Reinforcement Learnings-KI ist eine viel komplexere KI, die viel mehr Berechnungen durchführt als die KI, die für das überwachte Lernen verwendet wird.
DieHerausforderung dieser Aktivität besteht darin, zu verstehen :
- Wie der Roboter eine Entscheidung trifft.
- Wie sich ihre Entscheidung im Laufe des Trainings verändert.
- Wie der Roboter Hindernissen ausweicht und sich in der Arena bewegt, ohne die Wände zu berühren.
- Belohnungssysteme verstehen
Der große Unterschied zwischen dem überwachten Lernen und dem Lernen durch Reinforcement Learning liegt im Belohnungssystem. Wie Sie sehen können, gibt es jetzt diese beiden Blöcke "Belohnung" und "Stufe" am unteren Bildschirmrand. Aber was bedeuten sie?
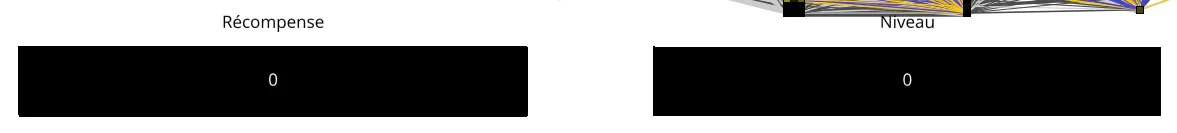
Jede Aktion wird mit einer Belohnung zwischen -100 und 100 belohnt. Die Stufe ihm entspricht dem Durchschnitt aller Belohnungen.
Vorrücken = +100
Nach rechts/links drehen = +55
Beim Drehen rückwärts gehen = -50
Wenn die Räder blockieren, erhält der Roboter eine Belohnung von -50
Ebenso wie wir Menschen erhält der Roboter gerne positive Belohnungen und mag keine negativen Belohnungen.
Der Roboter wird also die verschiedenen Aktionen, die er ausführen kann, ausprobieren, und zwar zunächst völlig zufällig, wird dann aber schnell feststellen, dass bestimmte Aktionen ihm bessere Belohnungen bringen als andere, und wird versuchen, diese zu maximieren und dann zu optimieren. Das Niveau stellt den Durchschnitt aller gesammelten Belohnungen dar und gibt einen guten Hinweis auf das allgemeine Niveau des Roboters, d. h. auf seine Fähigkeit, sich in der Arena zu bewegen und dabei den Wänden auszuweichen. Wenn man eine große Anzahl von Versuchen simuliert, erreicht das Niveau seinen Höhepunkt bei etwa 80-90. Auf diesem Niveau erhält der Roboter fast gar keine negativen Belohnungen mehr und der Durchschnitt steigt mit der Zeit nur noch an.

Der Trick bei der Programmierung einer künstlichen Intelligenz durch Reinforcement Learning besteht darin, die größten Belohnungen auf die Handlungen anzuwenden, die sie beherrschen soll.
Zum Beispiel wurde eine Intelligenz, die lernen sollte, an einem bestimmten Parkplatz einzuparken, so programmiert, dass sie eine Belohnung erhielt, die immer positiver wurde, je näher sie dem Parkplatz kam, und immer negativer, je weiter sie sich davon entfernte.
Das Belohnungssystem ist die Lernmethode, die unserer eigenen Lernen am nächsten kommt. Tatsächlich funktioniert unsere Art zu unterrichten auch mit einem Belohnungssystem. Um den Schüler:innen beim Lernen zu helfen, wurde das Notensystem erfunden; Schüler:innen, die ihre Lektion gut gelernt haben, werden belohnt und die anderen bestraft.