Entdecken Sie unsere Lehrmaterialien



Material :
- mindestens 1 Roboter
- 1 Computer/Roboter
- Flache Umgebung
Einstellungen :
- Überwachtes Lernen - Kamera
Dauer :
1,5 Stunden (2*45 min)
Alter :
8 Jahre und älter
Empfohlen zum Entdecken durch Manipulation
Bringen Sie Ihrem Roboter bei, auf bestimmte Situationen zu reagieren!
In dieser Aktivität lernen Sie, wie Sie die AlphAI-Software und das neuronale Netz einrichten, um Mbot in einer einfachen Umgebung zu betreiben.
Material
Ein Computer mit einer Webcam.
Post-it-Zettel in vier verschiedenen Farben oder kleine Blätter Papier, auf die große farbige Pfeile gezeichnet wurden. Beispiele unten.
Konfiguration
Die Konfiguration der Software kann manuell oder automatisch erfolgen.
Um es automatisch einzurichten :
Einstellungen > Beispielparameter laden > Überwachtes Lernen - Hindernisvermeidung (einfach)
Die Einrichtung kann auch manuell vorgenommen werden, indem Sie den nebenstehenden Anweisungen folgen.
- Sensoren > Kamera 21*16

- Aktionen > Weitergehen , Drehen , Zurückgehen , Anhalten
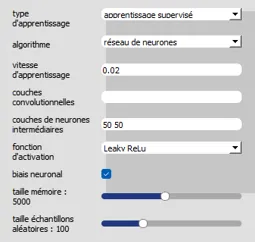
- IA > Lernart "Überwachtes Lernen", Algorithmus" Neuronales Netz ", Lerngeschwindigkeit" 0.02 ",Convolutional Layer:leer,Intermediate Neuronal Layer: 50 50.
Ebene 1
Eine Farbe erkennen
Für jede der Aktionen vorwärts, rückwärts, links oder rechts abbiegen :
- Wählen Sie eine Farbe, die Sie dieser Aktion zuweisen möchten.
- Platzieren Sie das Post-it in dieser Farbe vor der Computerkamera.
- Drücken Sie auf das Symbol für die entsprechende Aktion (oder verwenden Sie die Tastatur). Der Roboter führt die angeforderte Aktion aus und merkt sich die Zuordnung dieses Bildes zu dieser Aktion.

= Vorwärts

= Zurück

=links abbiegen

=Rechts abbiegen
Anhalten
Nun müssen wir dem Roboter beibringen, anzuhalten, wenn er keine farbigen Post-it-Zettel im Bild sieht.
Klicken Sie auf die Aktion Anhalten (schwarzes Quadrat), wenn kein Post-it in der Kamera zu sehen ist. Der Roboter bewegt sich nicht, aber er merkt sich die Assoziation dieses Bildes mit der Aktion Anhalten.
Sie können überprüfen, ob die Assoziation gespeichert wurde, indem Sie die Größe des Erfahrungsspeichers oben auf dem Bildschirm ablesen.

=Aufhören
.
Nachdem das Training des Roboters nun abgeschlossen ist, aktivieren Sie einfach den autonomen Modus, indem Sie auf die entsprechende Schaltfläche klicken oder die Leertaste drücken.
Bewaffne dich mit deinen bunten Post-its und halte sie vor die Kamera, um den Roboter zu steuern!

Verständnis
Wie trifft der Roboter Entscheidungen?
Deaktivieren Sie den Standalone-Modus, indem Sie auf die Schaltfläche klicken oder die Leertaste drücken.
Jedes Pixel des Bildes wird in 3 Farben zerlegt: Rot, Grün und Blau. Auf dem Bildschirm sieht man also 3 einfarbige Versionen des Bildes, die, wenn sie übereinandergelegt werden, das Farbbild ergeben.
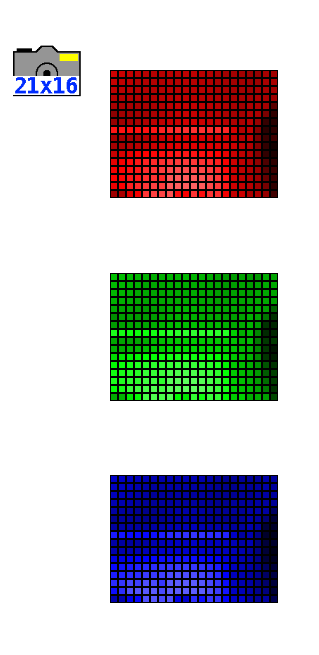
Achtung: Hier geht es um die additive Farbsynthese, nicht zu verwechseln mit den Primärfarben in der Malerei! (Die einer subtraktiven Synthese entsprechen).
Jedes Pixel eines monochromen Bildes ist mit einem Eingangsneuron verbunden, dessen Wert die Aktivierungsniveaus der nachfolgenden Schichten bis hin zur Ausgangsschicht berechnet.
Wie erkennt die Kamera Farben?
Die Farbe des Post-it beeinflusst die Pixel. Eine gelbe Farbe wird nämlich dadurch erkannt, dass der entsprechende Bereich im blauen Bild dunkler wird. Die gelbe Farbe ist eine Überlagerung von Rot und Grün, enthält aber kein Blau.
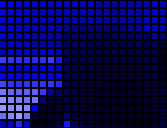
Blauer Kanal für ein gelbes Post-it

Für einen blauen Post-it
Das Prinzip ist bei den anderen beiden Farbkanälen das gleiche. Die Kamera wird also die auf den Post-it-Zetteln vorhandenen Farben unterscheiden und so dem Roboter ermöglichen, eine Entscheidung zu treffen.

Roter Kanal für das gelbe Post-it

Für den blauen Post-it
Wenn wir ein Post-it vor die Kamera halten, wie im folgenden Bild gezeigt, können wir sehen, dass die Kamera den Farbbereich gut erkennt.
Dies wirkt sich auf die Werte der Eingangsneuronen aus, die diese Information an die nachfolgenden Neuronenschichten weitergeben.

Wenn das neuronale Netz trainiert wird, führen die durchgeführten Berechnungen dazu, dass es der Aktion, die am besten zu den gespeicherten Daten passt, den höchsten Ausgabewert gibt.
Die Entscheidung, anzuhalten, beruht auf demselben Prinzip. Allerdings gibt es in diesem Fall keine Post-its! Das neuronale Netz erkennt stattdessen spezifischere Details im Bild (Person, Hintergrund usw.).

Die Berechnungen führen dazu, dass die Aktion Anhalten den höchsten Wert erhält, wenn diese Details erkannt werden.
⚠️L Der einzige Sensor, der bei dieser Aktivität vorhanden ist, ist die Kamera des Computers. Das bedeutet, dass der Roboter nicht in der Lage ist, zu erkennen, ob sich ein Hindernis vor ihm befindet. Es liegt vollständig an Ihnen, ihn zu führen, um ein Blockieren, einen Zusammenstoß oder einen Sturz zu vermeiden.
Ebene 2
Bewegen mit der Hand
Um die Bewegung des Roboters mit der Hand auszuführen, müssen Sie beim Training Ihres mBots mehr Sorgfalt an den Tag legen. Das bedeutet, dass Sie für ein optimales Training mehrere Lernpunkte für jede Aktion Ihres Roboters durchführen müssen.
Beim Üben ist es wichtig, darauf zu achten, dass der Hintergrund des Bildes (alles, was nicht Ihre Hand ist) ausreichend fixiert ist: derselbe Bildausschnitt, dieselbe Helligkeit, dieselbe Anzahl von Personen, die sich auf denselben Plätzen befinden, etc. Diese Regeln müssen auch während des Gebrauchs eingehalten werden!
Vorwärts, rückwärts, links abbiegen, rechts abbiegen
Platzieren Sie Ihre Hand im Vordergrund des Bildes.
Passen Sie die Position Ihrer Hand an die zu erlernende Handlung an.
Zeichnen Sie für jede Aktion mehrere Beispiele auf (z. B. 10 Datenpunkte pro Aktion).

= Vorwärts

Zurück

=Links abbiegen

= Nach rechts abbiegen
Anhalten
Wie im vorherigen Teil müssen wir dem Roboter beibringen, anzuhalten, wenn er keine Hand im Vordergrund des Bildes erkennt.
=Anhalten
Nachdem das Training des Roboters nun abgeschlossen ist, aktivieren Sie einfach den autonomen Modus, indem Sie auf die entsprechende Schaltfläche klicken oder die Leertaste drücken.
Halten Sie Ihre Hand wie beim Training vor die Kamera und beobachten Sie die Reaktionen des Roboters!
Verständnis
Die Funktionsweise der Kamera ist in beiden Lernprozessen gleich.
Diesmal soll das neuronale Netz jedoch lernen, die Position Ihrer Hand im Bild zu erkennen und nicht die Farbe eines Post-its. Dies ist eine komplexere Aufgabe für ein neuronales Netz, da es z. B. keine objektive Grenze zwischen einer Position in der Mitte und einer Position rechts davon gibt. Das Netz wird also selbst bestimmen müssen, wo die Grenzen zwischen den vier möglichen Positionen zu setzen sind.
Außerdem werden viele störende Elemente die Entscheidungsfindung des Netzwerks beeinträchtigen können. Das Netzwerk muss lernen, dass die Größe Ihrer Hand, ihre Form, die Position der Finger, ihre Ausrichtung usw. für die Entscheidungsfindung nicht wichtig sind: Nur die Position der Hand muss berücksichtigt werden. Deshalb sollte man für jede Art von Handlung mehrere Beispiele geben.
Auch der Bildhintergrund ist eine wichtige Störquelle. Deshalb ist es wichtig, auf einen möglichst festen Hintergrund zu achten.
Diese Stufe ermöglicht es Ihnen, ein flüssiges Ergebnis bei der Bewegung des Roboters zu erzielen, was mit einem besseren Verständnis der Funktionsweise der künstlichen Intelligenz einhergeht.
Währenddes Trainings
Während der Autonomie
=OK
Die Kamera befindet sich in der gleichen Position und gibt für beide Phasen die gleichen Informationen zurück. Der Roboter konzentriert sich auf meine Hand und nicht auf den Hintergrund.
💡Tipp: Wenn Sie diese Aktivität allein durchführen, achten Sie darauf, dass Sie den Roboter beobachten können, ohne Ihren Kopf während des Trainings und der Selbstständigkeit zu bewegen.
Explizite Verzerrungen
Heutige KIs arbeiten mit maschinellem Lernen anhand von Beispielen. Diese Beispiele werden als Lerndaten bezeichnet. Die Qualität des erzielten Ergebnisses hängt daher in erster Linie von der Qualität dieser Lerndaten ab.
Beim maschinellen Lernen versucht man, in den Lerndaten das Vorhandensein von zwei Arten von Verzerrungen zu vermeiden (d. h. Fehler, unerwünschte Phänomene oder generell Abweichungen zwischen dem gewünschten und dem erzielten Ergebnis).
Die erste Art von Verzerrung wird als explizite Verzerrung bezeichnet. Hierbei handelt es sich um einen menschlichen Fehler bei der Klassifizierung während des Trainings der KI. Beispiel: Wenn man den Roboter angewiesen hat, rückwärts zu fahren, wenn die Kamera das untenstehende Bild sieht (z. B. weil man versehentlich die falsche Taste gedrückt hat).
+

(Rückwärts)
=Expliziter Bias
In diesem Fall wird das neuronale Netz aufgrund dieses Widerspruchs in seinen Lerndaten Schwierigkeiten haben, eine Entscheidung zu treffen, wenn die Kamera ein ähnliches Bild beobachtet.
Um diese Art von Verzerrung zu beseitigen, müssen diese in den Daten vorhandenen Fehler einfach entfernt werden.

Implizite Verzerrungen
Implizite Verzerrungen sind schwieriger zu erkennen, da es sich hierbei nicht um objektive Fehler handelt, sondern vielmehr um eine mangelnde Vielfalt der Daten, die nicht ausreichen, um alle Fälle abzudecken, die bei der Verwendung auftreten.
Hier ist eine einfache Regel, die Sie sich merken sollten: Wenn die KI mit einer Situation konfrontiert wird, die sich zu sehr von all ihren Lerndaten unterscheidet, dann ist die Entscheidung der KI angesichts dieser Situation unvorhersehbar!
Um dies zu vermeiden, muss beim Training besonders darauf geachtet werden, eine Vielfalt an Beispielen zu erzeugen, die repräsentativ für die Situationen sind, die die KI bei ihrem Einsatz wahrscheinlich vorfindet.
Trainingsdaten


Zu analysierendes Bild
Welche Entscheidung wird die KI treffen?
Wie können die Trainingsdaten verbessert werden, um sicherzustellen, dass diese Entscheidung richtig ist? (Hinweis: Es sollten vier Beispiele verwendet werden).