Entdecken Sie unsere Lehrmaterialien



BenötigteMaterialien:
- 1 Roboter
- 1 Computer
- 1 Luftballon (vorzugsweise grün)
- Empfohlen: Armatur und Schnur, um den Ball in die Höhe zu hängen, Arena
Die + dieser Aktivität :
- Spielerisch
- Beliebt bei allen Altersgruppen
- Perfekt, um das Prinzip des verstärkenden Lernens einzuführen
Dauer :
40 bis 60 Minuten
Alter :
+ 8 Jahre
Software-Konfiguration:
Modus "Ballonverfolgung (grün)"
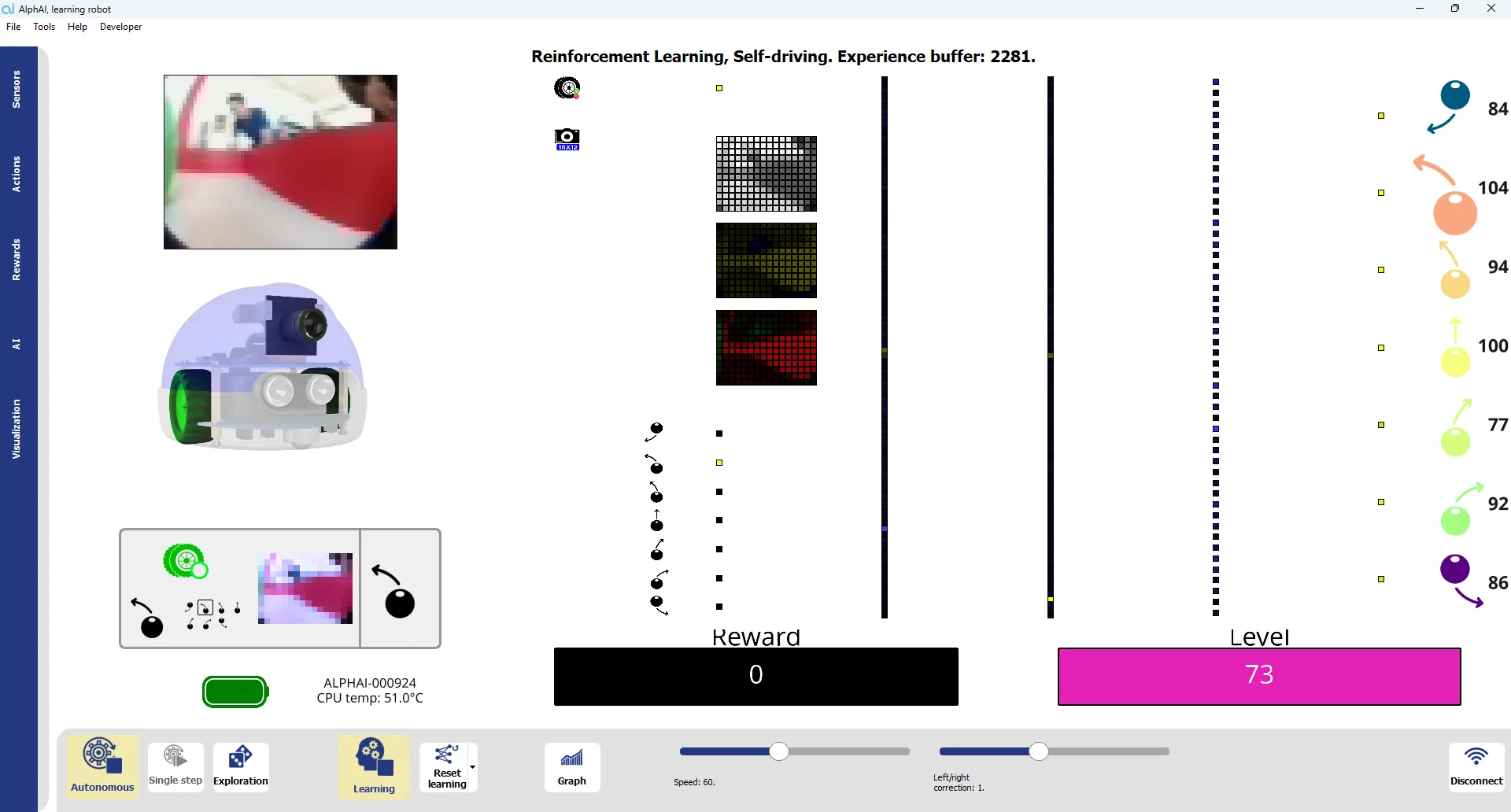
Ziel ist es, das Lernen durch Reinforcement Learning zu nutzen, um den Roboter darauf zu trainieren, einem Ball zu folgen. Basierend auf dem Prinzip von Try and Error passt der Roboter sein Verhalten allmählich als Reaktion auf Rückmeldungen aus seiner Umgebung an, die durch Belohnungen repräsentiert werden.
Einführung
Baue deine Arena mit einem grünen Ball, der in der Mitte hängt und als visuelle Orientierung für den Roboter dient. Dieser muss lernen, ihm zu folgen, während er den Raum erkundet. Sorgen Sie für einen guten Boden-Wand-Kontrast, eine gleichmäßige Beleuchtung und einen sauberen Boden, um eine zuverlässige Erkennung, eine reibungslose Bewegung und optimale Beobachtungsbedingungen zu gewährleisten.
Einstellungen
Verbinden Sie den Roboter an den Computer an und wählen Sie dann die Beispielkonfiguration "Ballonverfolgung (grün)".
Es ist wichtig zu überprüfen, dass, wenn der Roboter auf den Ball schaut, die grünen Pixel des Balls richtig erkannt werden. Dies äußert sich darin, dass auf dem von der Kamera erfassten Bild kleine gelbe Markierungen zu sehen sind. An anderer Stelle im Bild dürfen keine weiteren grünen Pixel zu sehen sein.


Ist dies nicht der Fall, müssen Sie die Einstellungen für die Farberkennung auf dem Reiter "Belohnungen" anpassen, um ein zufriedenstellendes Ergebnis zu erzielen.

Stellen Sie außerdem sicher, dass der Ballon auch dann noch richtig erkannt wird, wenn er aus verschiedenen Winkeln betrachtet wird.
Training
Aktivieren Sie die Schaltfläche "Selbstständig", um die Lernphase zu starten.
Der Roboter tritt dann in die Erkundungsphase ein, in der er eine auf Try and Error basierende Strategie verfolgt. Er führt verschiedene Aktionen nach dem Zufallsprinzip aus, um die Möglichkeiten zu erkunden, die sich ihm bieten. Diese Phase ist entscheidend dafür, dass der Roboter die Konsequenzen seiner Entscheidungen selbst entdeckt.
Bei jeder ausgeführten Handlung erhält der Roboter eine Rückmeldung in Form einer positiven, negativen oder gar keiner Belohnung . Dieser Mechanismus veranlasst ihn, vorteilhafte Verhaltensweisen zu bevorzugen und ineffektive oder kontraproduktive zu vermeiden. Nach und nach verfeinert er seine Strategie und verbessert seine Leistung.
Sie werden eine deutliche Veränderung in seinen Handlungen feststellen können: Zufällige und irrelevante Bewegungen werden seltener, während effektive Verhaltensweisen stärker werden. Der Roboter neigt also dazu, sich immer mehr auf sein vorher festgelegtes Endziel zu konzentrieren.
Test des Lernens
Wenn das Verhalten des Roboters konsistent wird (d. h. er folgt dem Ball effizient und gleichmäßig) : Deaktivieren Sie die Schaltfläche "Erkunden".
In dieser Phase wendet der Roboter nur die Aktionen an, die er als am effektivsten gelernt hat, ohne eine zufällige Erkundung einzuführen. Dies gewährleistet einen stabileren, vorhersehbareren und optimierten Betrieb, der auf den Erfahrungen aus der Erkundungsphase beruht.
Schlussfolgerung
Wir haben hier einen Algorithmus für das Lernen durch Reinforcement Learning verwendet. Durch eine Phase von Try and Error, die durch ein Belohnungssystem gesteuert wird, lernt der Roboter nach und nach, ein optimales Verhalten bei der visuellen Verfolgung anzunehmen.
In jedem Schritt führt der Agent eine Aktion aus, die den Zustand der Umgebung verändert. Der Agent muss nun entscheiden, ob er die Umgebung weiter erkundet, um neue Belohnungen zu entdecken, oder ob er sein aktuelles Wissen nutzt, um die kostengünstigsten Aktionen in einem bestimmten Zustand auszuwählen. Dieses Verhalten spiegelt den grundlegenden Kompromiss beim verstärkten Lernen zwischen Exploration und Exploitation wider.
Eine erfolgreiche Lernstrategie beinhaltet daher eine schrittweise Reduzierung unnötiger Versuche sowie ein autonomes Verhalten, das im Laufe der Zeit immer angepasster und konsistenter wird.